Представьте, что вы пришли на прием к психотерапевту, выложили ему самые сокровенные тайны, рассказали о проблемах в бизнесе и даже продиктовали номер банковской карты, чтобы он сразу оплатил услугу. А через месяц узнаете, что ваш «доктор» обсуждает детали вашей личной жизни с незнакомцами, используя их как наглядные примеры на лекциях. Согласитесь, это было бы шокирующим нарушением доверия.
Именно в такой ситуации сегодня оказались миллионы пользователей чат-ботов с искусственным интеллектом. Мы часто воспринимаем диалоговые окна ChatGPT, DeepSeek или Claude как абсолютно приватное пространство, забывая, что по ту сторону экрана находится не живой человек, хранящий тайну, а сложный алгоритм, который живет по законам корпораций. Понимание того, куда уходят наши данные и какова цена бесплатного доступа к мощнейшему ИИ - это вопрос цифровой гигиены, который уже сегодня может уберечь вас от серьезных проблем.
Цифровой отпечаток: почему бот запоминает то, что ему не положено
Когда вы задаете вопрос чат-боту, ваше сообщение не исчезает в безвоздушном пространстве. Оно сохраняется на серверах компании-разработчика, и происходит это отнюдь не из праздного любопытства инженеров. Главная цель сбора диалогов - дообучение и улучшение моделей. Согласно недавним исследованиям, шесть ведущих американских компаний, включая OpenAI (создателя ChatGPT), Google и Anthropic (создателя Claude), по умолчанию используют пользовательские данные для тренировки своих алгоритмов . Это означает, что написанное вами сегодня может стать частью «учебника» для завтрашних версий нейросетей.
Сама по себе идея не нова, но она таит в себе скрытую угрозу. Представьте, что вы просите DeepSeek помочь вам сформулировать условия контракта для нового делового партнера и вставляете в запрос реальные коммерческие условия, включая сумму сделки. Или, скажем, просите ChatGPT проверить, не слишком ли простым является пароль от вашей корпоративной почты, попутно сообщив сам пароль для оценки. В этот момент конфиденциальная информация перестает быть вашей исключительной собственностью. Исследователи из Стэнфорда предупреждают: если вы делитесь коммерческой тайной или медицинскими данными в ChatGPT или Gemini, эта информация может быть использована для обучения, даже если вы отправили ее в отдельном файле, а не напечатали вручную .
Проблема усугубляется тем, что данные из чатов могут объединяться с информацией из других сервисов - ваших поисковых запросов, истории покупок и активности в соцсетях, создавая предельно детализированный цифровой портрет . И если сегодня вам кажется безобидным спросить у бота рецепт блюда с учетом вашего диабета, то завтра алгоритмы могут «вычислить» вас как часть уязвимой группы, что теоретически способно повлиять на решение страховой компании или даже работодателя, если эти данные утекут или будут переданы третьим лицам.
Эффект «отравленных» данных и угроза кибербезопасности
Может возникнуть резонный вопрос: зачем компаниям мои личные разговоры, если ИИ и так уже умный? Ответ кроется в так называемом «отравлении данных» (data poisoning). Это явление, при котором вредоносные или просто некачественные данные, попадая в обучающий массив, искажают поведение модели . Разработчикам жизненно важно получать чистые, разнообразные и «естественные» диалоги реальных людей, чтобы их детище не «глючило» и не теряло точность. Ваши живые запросы - это золотая жила для улучшения продукта. Однако, попадая в эту базу, ваш пароль или номер паспорта становится частью огромного датасета, доступ к которому имеют сотни инженеров и тестировщиков по всему миру.
Более того, сам факт хранения истории диалогов создает прямую угрозу цифровой безопасности. В 2023 году OpenAI была вынуждена временно остановить работу ChatGPT из-за ошибки, которая открывала одним пользователям доступ к чужим данным из истории запросов . Это доказывает: даже самые защищенные системы не застрахованы от сбоев. Если вы «скормили» боту коммерческую тайну, она физически существует на сервере, и будь то хакерская атака, внутренняя утечка или техническая ошибка - риск ее компрометации никогда не равен нулю.
Инструкция по защите: как перестать кормить «цифрового монстра»
К счастью, регуляторы и растущее беспокойство пользователей заставляют разработчиков идти на уступки. У большинства популярных платформ есть настройки, позволяющие если не полностью обезопасить себя, то хотя бы минимизировать использование ваших данных для обучения. Главное правило: никогда не оставляйте настройки по умолчанию. Рассмотрим алгоритмы действий для двух самых популярных систем - ChatGPT и DeepSeek.
ChatGPT: отключаем слежку за «улучшением» модели
OpenAI предоставляет пользователям инструмент под названием «Data controls». Чтобы ваши диалоги перестали использовать в качестве корма для новых версий ИИ, нужно выполнить простую последовательность действий. На компьютере, после входа в аккаунт, нажмите на свой профиль (иконка с вашим именем или фото) в правом нижнем углу. Выберите пункт «Settings» (Настройки), затем перейдите в раздел «Data controls» (Управление данными). Здесь вы найдете переключатель «Improve the model for everyone» (Улучшать модель для всех) - его необходимо деактивировать .
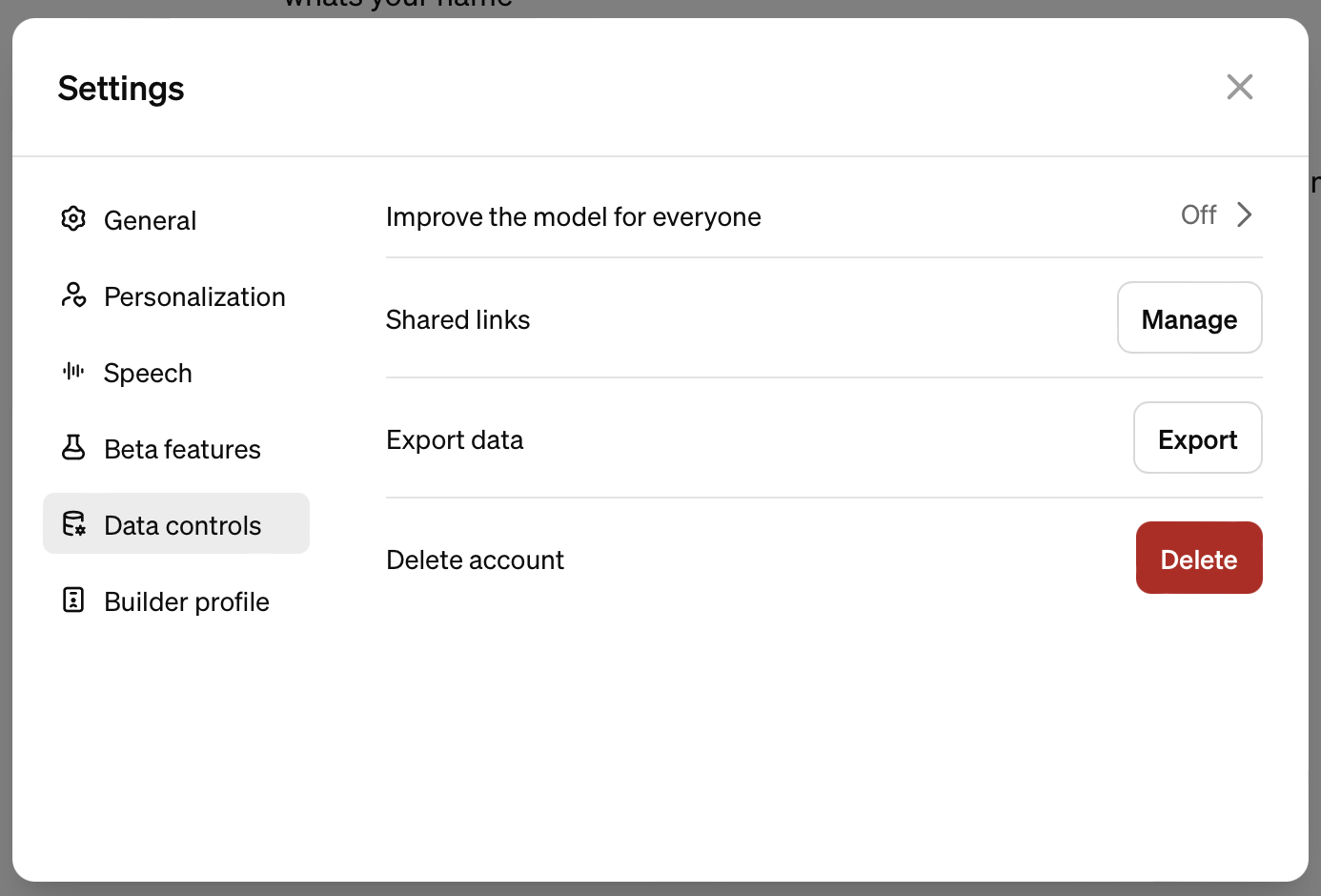
Важно понимать, что это не удаляет ваши старые диалоги, а лишь гарантирует, что новые беседы не пойдут на тренировку алгоритмов. Сами чаты останутся в вашей истории. Для максимальной конфиденциальности в ChatGPT существует функция «Временный чат» (Temporary chat). В этом режиме диалог не сохраняется в истории, не используется для обучения и удаляется с серверов через 30 дней . Активировать его можно через выпадающее меню выбора модели, где вместо обычного GPT-4o нужно выбрать пункт «Temporary chat».
DeepSeek: китайский подход к чистоте истории
DeepSeek, набирающий популярность китайский чат-бот, также позволяет пользователям управлять своими данными, хотя его интерфейс чуть менее прозрачен в вопросах политики конфиденциальности. Чтобы очистить историю или заблокировать её сохранение, вам нужно зайти в свой аккаунт на официальном сайте. Нажмите на аватар пользователя перейдите в настройки «Settings» (Настройки аккаунта) .
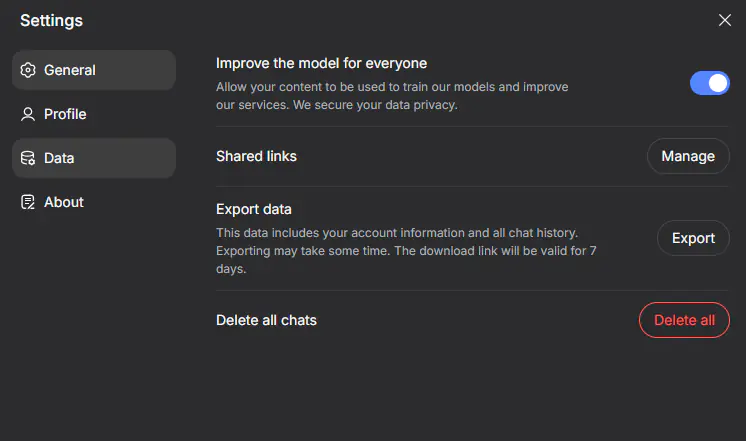
В левом меню выберите вкладку «Data» (Данные). Здесь вы найдете раздел управления активностью, где можно удалить всю историю чатов за всё время или за определенный период, нажав кнопку «Delete all» (Удалить все) . Там же, в настройках, следует найти опцию«Improve the model for everyone» (Улучшать модель для всех) и отключить её . Это предотвратит запись будущих разговоров. На мобильных устройствах алгоритм похож: через боковое меню нужно зайти в профиль и найти пункт «Удалить все чаты» .
Заключение: бдительность - новая вежливость в эпоху ИИ
Мы вступаем в эру, где границы между приватным и публичным стираются с пугающей скоростью. Чат-боты - это не просто программы, это зеркала, отражающие нашу жизнь, и отражают они её слишком подробно. Относитесь к диалогам с ИИ так, как если бы они были написаны на открытке, которую может прочитать почтальон.
Не сообщайте ботам пароли, номера документов, банковских карт и коммерческие тайны. Даже если вы отключили обучение модели, риск утечки данных из-за технических сбоев или хакерских атак сохраняется. Используйте временные чаты для особо чувствительных тем и регулярно чистите историю, как вы чистите файлы cookie в браузере. Ваши данные - это самый ценный ресурс современности, и только вы вправе решать, кому позволить на них взглянуть.