
Фреймворк аудита Linux - это мощный инструмент для аудита системных событий. От запуска исполняемых файлов до системных вызовов - всё может быть залогировано. Однако всё это аудит-логирование достигается ценой снижения производительности системы. Давайте посмотрим, как мы можем оптимизировать наши правила аудита.
Советы по производительности
Хорошая производительность auditd снизит нагрузку на ядро Linux и минимизирует его влияние. Прежде чем что-либо менять в системе, мы рекомендуем провести бенчмаркинг производительности до и после. Таким образом вы сможете увидеть преимущества ваших усилий по настройке.
Стратегия: Порядок правил - Правильное расположение правил в порядке обработки
Многие программные пакеты используют «обработку правил на основе порядка». Это означает, что каждое правило оценивается до тех пор, пока одно не сработает. Для демона аудита Linux этот принцип также применим.
Таким образом, одна из самых больших областей для настройки - это порядок правил. События, которые происходят чаще всего, должны быть вверху, а «исключения» — внизу.
Если ваша настройка аудита Linux выполнена в алфавитном порядке, можете быть уверены, что эта конфигурация не оптимизирована для производительности. Давайте продолжим настройку auditd в других областях.
Стратегия: Исключение событий - Определение типов сообщений, которые используются чаще всего
Проблема с логированием событий заключается в том, чтобы гарантировать запись всех важных событий, избегая при этом регистрации ненужных.
Некоторые администраторы применяют правило «просто логируй всё». Хотя это часто имеет смысл, это определенно неэффективно и снижает производительность ядра Linux. Такой вид логирования определенно увеличит время обработки для auditd и негативно скажется на производительности ядра.
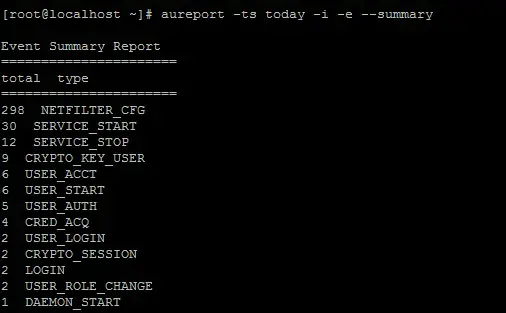
Чтобы улучшить логирование, нам сначала нужно определить, какие события появляются чаще всего.
Самые частые события, отсортированные по исполняемому файлу
| 1 | aureport -ts today -i -x --summary |
Самые частые события, отсортированные по системному вызову (syscall)
| 1 | aureport -ts today -i -s --summary |
Это покажет, какой исполняемый файл или системный вызов переполняет ваши журналы аудита. Указав -ts today, мы видим только недавние события.
Вывод aureport определенно помогает уменьшить объем логирования, отключая некоторые события. Конечно, вы можете сделать это также для событий, файлов и других типов. Подробности см. в man-странице aureport.
Игнорирование событий
Теперь, когда мы знаем, какие типы файлов, событий или других сообщений у нас есть, мы можем их игнорировать. Для этого мы должны создать правило, которое совпадает и содержит оператор exclude или exit never.
Оператор exit используется вместе с syscall, для других типов мы используем exclude.
Фильтрация по типу сообщения
Например, чтобы отключить все сообщения «CWD» (текущий рабочий каталог), мы можем использовать такое правило:
| 1 | -a exclude,always -F msgtype=CWD |
Поскольку срабатывает первое совпадение, исключения должны быть помещены в начало цепочки правил. Поскольку это фильтр на основе типа сообщения, мы используем exclude.
Фильтрация по нескольким правилам
Другой пример — подавление сообщений, записываемых инструментами VMware. Для этого мы объединяем несколько правил, предоставляя несколько параметров -F. Разрешено до 64 полей, но обычно достаточно нескольких. При использовании -F каждое выражение проверяется оператором логического И (AND). Это означает, что все поля должны быть истинными, чтобы сработало действие набора правил аудита.
| 1 2 | -a exit,never -F arch=b32 -S fork -F success=0 -F path=/usr/lib/vmware-tools -F subj_type=initrc_t -F exit=-2 -a exit,never -F arch=b64 -S fork -F success=0 -F path=/usr/lib/vmware-tools -F subj_type=initrc_t -F exit=-2 |
Примечание: некоторые примеры могут давать разные результаты на старых машинах. Поэтому всегда тестируйте каждое правило, чтобы убедиться, что оно работает. Правила, которые ничего не делают, негативно влияют только на производительность.
Стратегия: Определение потребностей в буферизации
По умолчанию auditctl может предоставить некоторую статистику при использовании флага -s (status). Он показывает свой статус (enabled), любые связанные флаги, идентификатор процесса (PID) и статистику, связанную с журналом (backlog, rate, lost).
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # auditctl -s enabled 1 flag 1 pid 430 rate_limit 0 backlog_limit 320 lost 0 backlog 0 enabled -1 flag 0 pid 0 rate_limit 0 backlog_limit 320 lost 0 backlog 0 |
Разрешение больших буферов означает более высокую потребность в ресурсах памяти. В зависимости от вашей машины это может быть небольшой жертвой, чтобы гарантировать регистрацию всех событий.
Чтобы определить наилучший возможный размер буфера, следите за значениями backlog. Они не должны превышать параметр backlog_limit (в нашем случае 320). Другая полезная статистика - отслеживание значения lost, так как оно покажет, сколько событий не удалось обработать. На нормальной системе это значение должно быть равно или близко к нулю.
Стратегия: Мониторинг каталогов
Используйте path вместо dir при мониторинге конкретного каталога. Есть два способа отслеживать содержимое каталога: path или dir.
В зависимости от того, что вы хотите отслеживать, мониторинг подкаталогов может не потребоваться. В таком случае лучше использовать опцию path, так как она отслеживает только этот конкретный каталог. Это небольшая корректировка, которая может сэкономить вам много ненужного аудит-логирования.


