Глобальный интернет столкнулся с масштабными перебоями в работе 18 ноября, когда технический сбой в инфраструктуре компании Cloudflare привел к недоступности тысяч популярных онлайн-сервисов. Миллионы пользователей по всему миру внезапно потеряли доступ к привычным цифровым ресурсам, от социальных сетей до игровых платформ.
Инцидент начался в середине дня и практически сразу приобрел глобальный характер. Пользователи сообщали о невозможности загрузки страниц в социальной сети X (ранее известной как Twitter), киноплатформе Letterboxd, а также множестве других сервисов. Вместо ожидаемого контента они сталкивались с ошибками 500 Internal Server Error, фирменными страницами Cloudflare с уведомлениями о проблемах или бесконечной загрузкой.
Cloudflare относится к числу ключевых инфраструктурных компаний интернета, чья работа обычно остается незаметной для конечных пользователей. Компания предоставляет услуги CDN (Content Delivery Network - сеть доставки контента), ускоряет загрузку веб-страниц, фильтрует вредоносный трафик и помогает сайтам выдерживать интенсивные нагрузки. Когда такая система дает сбой, последствия мгновенно распространяются на все зависимые сервисы.
Особенностью текущего инцидента стало то, что проблемы затронули не только конечные сайты, но и внутренние системы управления Cloudflare. По данным технических изданий, стали недоступны панель управления сервисом и программные интерфейсы API (Application Programming Interface - программный интерфейс приложения), которые используют администраторы для управления своими ресурсами. Это значительно осложнило процесс диагностики и устранения неполадок.
Эксперты по кибербезопасности отмечают, что инцидент наглядно демонстрирует уязвимость современной интернет-инфраструктуры, где множество сервисов полагаются на ограниченное число крупных провайдеров. Cloudflare обеспечивает защиту от DDoS-атак (Distributed Denial of Service - распределенный отказ в обслуживании) для миллионов сайтов, выступая важным элементом глобальной сетевой безопасности.
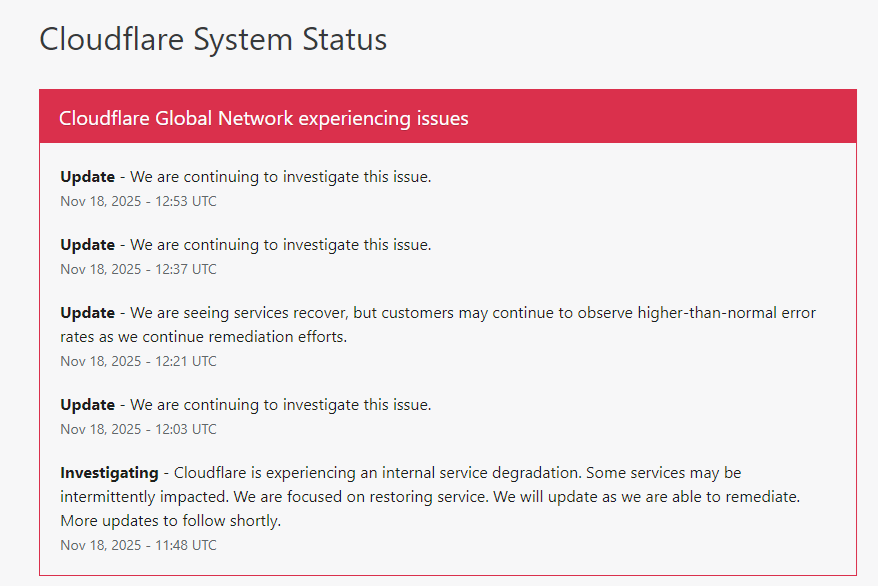
Технические специалисты компании оперативно отреагировали на ситуацию. В официальном статус-блоге Cloudflare появились сообщения о ведущихся работах по устранению неполадок. При этом первоначальные оценки масштаба сбора постоянно расширялись по мере поступления информации от пользователей из разных регионов мира.
Особую озабоченность у экспертов вызвал факт одновременного отказа нескольких систем мониторинга. Обычно подобные платформы имеют дублирующие механизмы контроля, но в данном случае сбой затронул основные каналы оповещения. Это привело к задержкам в оценке реальных масштабов проблемы.
Пострадавшие компании начали публиковать заявления в альтернативных каналах связи, включая другие социальные платформы и мессенджеры. Многие подчеркивали, что проблема носит внешний характер и связана исключительно со сбоем у провайдера услуг. Тем временем пользователи продолжали сообщать о проблемах с доступом к банковским приложениям, облачным хранилищам и корпоративным порталам.
Интересно, что географическое распределение проблем оказалось неравномерным. Некоторые регионы сообщали о полном отсутствии доступа к целым категориям сайтов, в то время как в других зонах сбои носили частичный характер. Это может указывать на каскадный характер отказа, когда проблемы постепенно распространялись по глобальной сети доставки контента.
Инцидент с Cloudflare стал уже не первым масштабным сбоем в работе ключевых интернет-инфраструктур за последние годы. Подобные события регулярно происходят у различных облачных провайдеров и сервисов доставки контента, каждый раз демонстрируя зависимость современного интернета от надежности ограниченного числа технологических компаний.
Пока технические специалисты продолжают работу по восстановлению нормального функционирования сервисов, эксперты призывают пересмотреть подходы к построению отказоустойчивых архитектур. Многие рекомендуют организациям распределять критически важные сервисы между несколькими провайдерами, чтобы минимизировать риски подобных масштабных сбоев в будущем.
